In this tutorial, we are going to talk about web scraping using python.
Firstly, we have to discuss about what is web scraping technique? Whenever we need the data (it can be text, images, links and videos) from web to our database. Lets discuss where we should need the web scraping in real world.
- Nowadays, we have so many competitors in each and every field for surpassing them we need their data from the website or Blogs to know about products, customers and their facilities.
- And Some Admin of Particular website, blogs and youtube channel want the reviews of their customers in database and want to update with this In, this condition they use web scraping
There are many other areas where we need web scraping, we discussed two points for precise this article for readers.
Do you want to become certified Python Programmer? Then Intellipaat Python Certification course is for you.
Prerequisites:
You just have basic knowledge of python nothing else so, get ready for learning web scraping.
Which technology we should use to achieve web scraping?
We can do this with JavaScript and python but according to me and most of the peoples, we can do it with python easily just you should know the basic knowledge of python nothing else rest of the things we will learn in this article.
Python Web Scraping Tutorial
1. Retrieving Links and Text from Website and Youtube Channel through Web Scraping
- In this first point, we will learn how to get the text and the links of any webpage with some methods and classes.
We are going to do this beautiful soup method.
1. Install BS4 and Install lxml parser
- To install BS4 in windows open your command prompt or windows shell and type: pip install bs4
- To install lxml in windows open your command prompt or windows shell and type: pip install lxml
Note: “pip is not recognized” if this error occurs, take help from any reference.
To install BS4 in ubuntu open your terminal:
- If you are using python version 2 type: pip install bs4
- If you are using python version 3 type: pip3 install bs4
To install lxml in ubuntu open your terminal
- If you are using python version 2 type: pip install lxml
- If you are using python version 3 type: pip3 install lxml
2. Open Pycharm and Import Modules
Import useful modules:
import bs4
import requests

Then take url of particular website for example www.thecrazyprogrammer.com
url= "http://thecrazyprogrammer.com/" data=requests.get(url) soup=bs4.BeautifulSoup(data.text,'htm.parser') print(soup.prettify())
And now you will get the html script with the help of these lines of code of particular link you provided to the program. This is the same data which is in the page source of the website webpage you can check it also.

Now we talk about find function() with the help of find function we can get the text, links and many more things from our webpage. We can achieve this thing through the python code which is written below of this line:
We just take one loop in our program and comment the previous line.
for para in soup.find('p')
print(para)

And we will get the first para of our webpage, you can see the output in the below image. See, this is the original website view and see the output of python code in the below image.

Pycharm Output

Now, if you want all the paragraph of this webpage you just need to do some changes in this code i.e.
Here, we should use find_all function() instead find function. Let’s do it practically

You will get all paragraphs of web page.
Now, one problem will occur that is the “<p>” tag will print with the text data for removing the <p> tag we have to again do changes in the code like this:

We just add “.text” in the print function with para. This will give us only text without any tags. Now see the output there <p> tag has removed with this code.
With the last line we have completed our first point i.e. how we can get the data (text) and the html script of our webpage. In the second point we will learn how we get the hyperlinks from webpage.
2. How to Get All the Links Of Webpage Through Web Scraping
Introduction:
In this, we will learn how we can get the links of the webpage and the youtube channels also or any other web page you want.
All the import modules will be same some changes are there only that changes are:
Take one for loop with the condition of anchor tag ‘a’ and get all the links using href tag and assign them to the object (you can see in the below image) which taken under the for loop and then print the object. Now, you will get all the links of webpage. Practical work:

You will get all the links with the extra stuff (like “../” and “#” in the starting of the link)
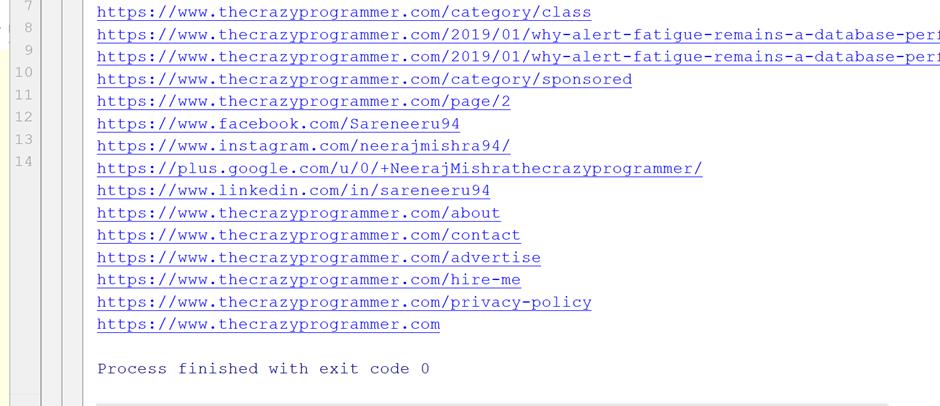
- There is only some valid links in this console screen rest of them are also link but because of some extra stuff are not treating like links for removing this bug we have to do change in our python code.
- We need if and else condition and we will do slicing using python also, “../” if we replace it with our url (you can see the url above images) i.e. http://thecrazyprogrammer.com/, we will get the valid links of the page in output console let see practically in below image.

In the above image we take the if condition where the link or you can say that the string start with the “../” start with 3 position of the string using slice method and the extra stuff like “#” which is unuseful for us that’s why we don’t include it in our output and we used the len() function also for printing the string to the last and with the prefix of our webpage url are also adding for producing the link.
In your case you can use your own condition according to your output.
Now you can see we get more than one link using if condition. We get so many links but there is also one problem that is we are not getting the links which are starting with “/” for getting these links also we have to do more changes in our code lets see what should we do.
So, we have to add the condition elif also with the condition of “/” and here also we should give “#” condition also otherwise we will get extra stuff again in below image we have done this.

After putting this if and elif condition in our program to finding all the links in our particular webpage We have got the links without any error you can see in below image how we increased our links numbers since the program without the if and elif condition.

In this way we can get all the links the text of our particular page or website you can find the links in same manner of youtube channel also.
Note: If you have any problem to getting the links change the conditions in program as I have done with my problem you can use as your requirement.
So we have done how we can get the links of any webpage or youtube channel page.
3. Log In Facebook Through Web Scraping
Introduction
In this method we can login any account of facebook using Scraping.
Conditions: How we can use this scarping into facebook because the security of Facebook we are unable to do it directly.
So, we can’t login facebook directly we should do change in url of facebook like we should use m.facebook.com or mbasic.facebook.com url instead of www.facebook.com because facebook has high security level we can’t scrap data directly.
Let’s start scrapping.
This Is Webpage Of m.facebook.com URL
Let’s start with python. So first import all these modules:
import http.cookiejar
import urllib.request
import requests
import bs4
Then create one object and use cookiejar method which provides you the cookie into your python browser.
Create another object known as opener and assign the request method to it.
Note: do all the things on your risk don’t hack someone id or else.
Cj=http.cookiejar.Cookiejar() Opener=urllib.request.build_opener(urllib.request.HTTPcookieProcessor) Urllib.request.install_opener(opener) Authentication_url=""

After this code, you have to find the link of particular login id through inspecting the page of m.facebook.com and then put the link into under commas and remove all the text after the login word and add “.php” with login word now type further code.

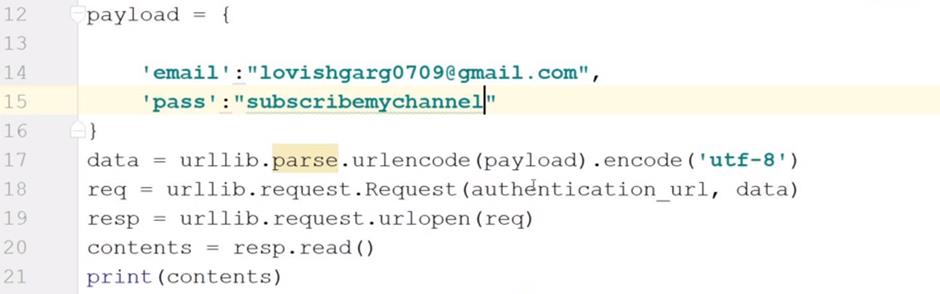
payload= {
'email':"xyz@gmail.com",
'pass':"(enter the password of id)"
}
After this use get function give one cookie to it.
Data=urllib.parse.urlencode(payload).encode('utf-8')
Req=urllib.request.Request(authentication_url,data)
Resp=urllib.request.urlopen(req)
Contents=resp.read()
Print(contents)
With this code we will login into facebook and the important thing I have written above also do it all things on your risk and don’t hack someone.
We can’t learn full concept of web scraping through this article only but still I hope you learned the basics of python web scrapping.